What does it take to train a large language model? This month, The Information reported that OpenAI spent over $120MM in two years on cloud computing, primarily training large language models. This is a staggering outlay for a company that was, at the time, still in closed beta. For comparison, Lyft and Slack each committed to spending approximately $50MM on cloud computing in 2019 – the same year the rideshare company served 23MM riders and the business messenger connected 12MM workers.
Nobody knows for sure the singular value of large language models (LLMs), but many believe they will revolutionize human computer interfaces. LLMs have already been used to improve natural language search, conversational analysis and text summarization. They already enhance billions of interactions on people’s favorite websites and devices. Now, startups and big companies alike are harnessing LLMs (if not building them in house) to create natural-sounding chat and voice bots.
At Gridspace, we have found novel ways to efficiently train world-class language models using focused, proprietary conversational data sets and interruptible, high-performance compute (HPC) infrastructure. This year, we have trained language models on GPUs, TPUs and IPUs. We have leveraged hyperscalers and our local research clusters. We have even used emerging clouds like Crusoe Cloud for AI research using role-play data. Crusoe Cloud provides environmentally friendly (and inexpensive) GPUs powered by flared gas.
While our R&D cloud bill will come in under $60MM this year, our current results speak louder than our spend! Gridspace currently outperforms OpenAI Whisper and Amazon Alexa on a variety of important data sets. We have also demonstrated these results in online mode and with Fortune 500 customers. You can try Gridspace for yourself by registering for an account here.
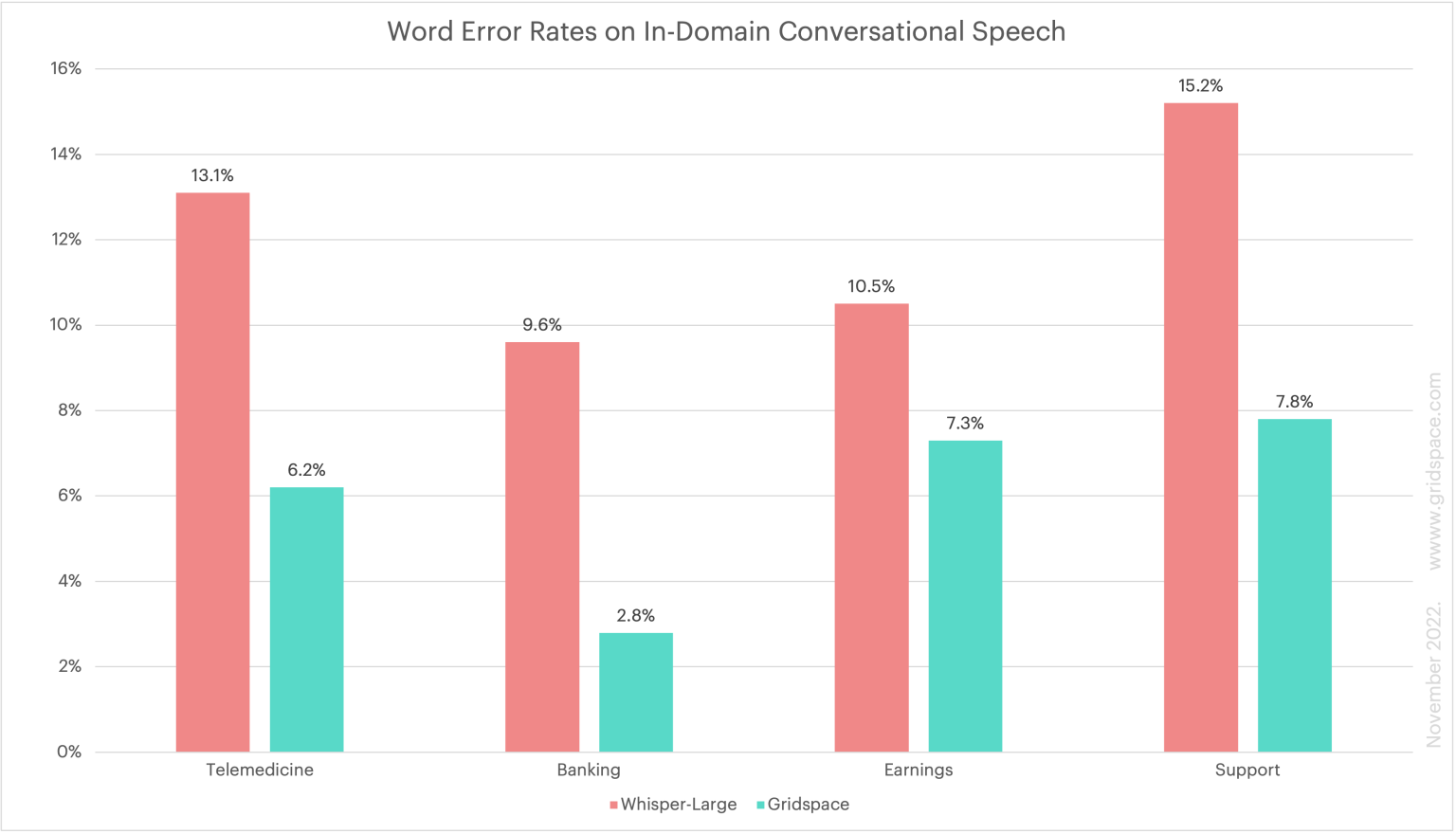
The above chart shows word error rates (WER) from Gridspace and Whisper on a variety of in-domain conversational speech data sets. While Whisper’s WERs are very impressive for a general model, the model’s performance is not superhuman on real-world calls. Gridspace’s in-domain models (shown in green) beat Whisper by over 50% on several benchmark tests for telemedicine, banking and support calls.
We have learned a lot from productizing our speech and language AI work. When we operate workflow software and work closely with customers, we can scope AI experiments very tightly. We benefit from customer feedback and usage data – not just benchmarks on people reading old newspapers. In our business, we work closely with real contact center operators. Contact centers generate a lot of conversational data but not always the necessary metadata to train useful models.
An AI-product mindset focused on customer outcomes really helps here. Since we know what data we have, what data we don’t have, and what our customers’ primary pains around automation are, we don’t have to brute force AI solutions. We can curate focused data sets and improve our product workflows to collect better annotations before retraining a new model. Ironically, we have found this approach leads to new ideas and strategies for building more powerful, general pre-trained models.
Hyperscalers and IaaS disruptors have also helped us remain competitive. When they bring new HPC capacity online for themselves, they eventually lower costs for everybody else. No wonder NVIDIA’s data center segment has grown at 66% CAGR in the last five years. With more companies looking to save on cloud computing and certain HPC use cases falling out of favor, we anticipate more opportunities to scale up new LLM training experiments. We also anticipate even more semiconductor innovations, which accelerate the most promising directions of AI experimentation.
Even as training costs come down, does it make sense for more companies to train LLMs? And more generally, when should companies be AI consumers vs. builders? No matter your cloud budget, AI product engineering still takes copious amounts of data, AI talent and operational expertise. And the less focused the AI objective, the less likely any amount of data, AI talent, and HPC budget will deliver useful results. Money may talk, but when it comes to LLMs, they can’t talk about everything yet.